Préambule
Pour moi la supervision des serveurs linux est des plus intéressantes :
- C’est un système ouvert
- L’Os est suffisamment robuste pour permettre de prendre la main sur le serveur même si un service est défaillant
- Il n’y a pas ou très peu de boite noires
- Les fichiers de logs sont suffisamment parlant pour connaitre le hic 😀
- Avec une gestion par fichier, la gestion du serveur est relativement simple
La supervision d’un serveur Linux peut paraître simple.
Pour paraphraser la première phrase de « Linux pour les nuls » : Tout est fichier 😀
Une fois que l’on a dit cela, on a tout dit et rien dit non plus 😛
Essayons de comprendre le fonctionnement d’un serveur Linux.
Plusieurs aspects sont à prendre en compte :
- Le noyau de linux (je ne parlerais que des Os rencontrés en entreprise) :
- Façon Debian
- Façon RedHat
- Façon SuSe (même si c’est assez proche de RedHat)
- Gestion du démarrage du serveur en fonction de la version de l’OS
- Debian
- Depuis Debian 9 : systemD
- Avant Debian 8 : initD ou systemD
- Avant debian 8 : initD
- RedHat
- Depuis RedHat7 : SystemD
- Avant RedHat7 : initD
- Debian
Il faut prendre en compte également ces différents.
Par exemple :
- iptables est devenu firewalld
- Le nom des interfaces à changer
- Les outils de gestion des paquets diffèrent
- Debian : apt-get
- RedHat : yum
- SuSe : zipper ou yast2
- Et ce ne sont pas les seuls différences et ce n’est pas le sujet de l’article 😀
La supervision doit être capable de prendre en compte ces différents aspect, sans rendre la maintenance de la supervision plus complexe.
Dans la suite de l’article nous allons donc mettre en place les templates nécessaires pour la supervision d’un serveur linux en fonction du noyaux et de la version.
NB : Je ne parlerais donc pas des distributions « Exotiques » dans cet article 😀
Création des templates d’hôtes
La démarche
- Dans un premier temps nous allons créé un template générique à Linux
- Deuxième étape il faut définir les distributions à superviser
- Dernière étape on défini la version de la distribution
Prérequis
Dans un premier temps il faut mettre en place une supervision suffisante, permettant de dire mon serveur fonctionne (on parle bien du serveur pas des applications hébergées).
Ma démarche et de mettre en place une supervision le moins invasible possible.
Linux fourni un outil merveilleux ( Je sais c’est pas le seul 😀 ) SNMP
En partant de là plusieurs problèmes se posent d’un point de vue sécurité :
- Tout le monde peut interroger SNMP
- La communauté par défaut est connu de tout le monde, public
- Les modifications via SNMP sont possibles
- Seul les outils autorisés à faire du SNMP doivent être autorisés à se connecter.
Il va donc falloir sécuriser la connexion SNMP.
Configuration des flux SNMP
Coté réseau
Toute entreprise digne de ce nom, utilise des firewalls pour interdire les connexions non autorisées sur ses serveurs (SSH, SNMP, HTTP,…).
L’étape 1 consiste à demander l’ouverture des flux SNMP :
- Tous les pollers (ou une plage d’IP) sont autorisés à faire du SNMP
- Port UDP 161 pour SNMP
- Port UDP 162 pour les traps SNMP
Coté serveur
Le fait d’ouvrir un flux ne veut pas dire que tout le monde fait ce qu’il veux 🙂
Il faut sécuriser les connexion coté serveur (et c’est vrai pour tous les équipements supervisés : switch, routeur,…)
Nous allons donc définir le RACI (ITIL quand tu nous tiens 😀 ) sur chaque serveur Linux pour les connexion SNMP.
Les différentes étapes :
- Lister les serveurs autorisés à faire du SNMP
- Définir la communauté de supervision
Définir la communauté de supervision
Pourquoi mettre en place une communauté SNMP de supervision ?
La réponse est simple, la supervision n’est pas la seul à utiliser ce protocole :
- La supervision ne doit pas impacter les outils déjà en place :
- HP Insight pour les serveur HP
- IDRAC pour les serveur DELL
- …
- La communauté de supervision doit être le plus générique possible
- Contrairement à ce qui est souvent fait, c’est à dire, le nom de l’outil de supervision « est » la communauté :
- Personnellement, je préconise d’utiliser la communauté « supervision » ou « monitoring » ou une autre communauté, mais pas le nom de l’outil.
- Si vous changez d’outil de supervision RAS 😀
- Pas besoin de faire une demande de changement pour changer le nom de la communauté
- Le nom de la communauté est en rapport avec la fonction de la communauté
- Contrairement à ce qui est souvent fait, c’est à dire, le nom de l’outil de supervision « est » la communauté :
Configuration de /etc/snmp/snmpd.conf
Il faut rajouter une ligne pour chaque poller de supervision.
Pourquoi ?
Si il y a un soucis avec le poller, il faut basculer sur un autre 😀
Le fichier /etc/snmp/snmpd.conf contiendra donc :
rocommunity <communuaute SNMP> <IP des pollers de supervision>
read only est important pour ne pas ouvrir une faille de sécurité.
Une fois la configuration effectuée il suffit de redémarrer le service
service snmpd restart
et cela fonctionne aussi avec systemd. Etonnant non ? 😀
Préparons nos templates d’hôtes
Il va falloir prendre en compte 2 paramètres :
- La distribution
- La version de l’OS
Liste des distributions
Je ne vais pas faire le tour de toutes les distributions Linux.
Mais je pense que les exemples Debian et RedHat titillera votre imagination 😀
Pour cet article je vais donc me concentrer les deux principales utilisées en entreprise (SuSe étant marginal je ferais un article pour cet OS) :
- Debian
- RehHat
Je vous laisse le soin de faire les déclinaisons sur les distrib :
- Ubuntu
- Fedora
- CentOs
- Suse ( merci de faire part de votre retour d’expérience 😀 )
- Mint
- …
Liste des versions
Nous ferons donc des templates pour :
- RedHat :
- 6.x
- 7.x
- Debian
- 7.x
- 8.x
- 9.x
Les spécificités ne vous auront pas échapées
- Gestion du boot
- Démarrage des services
- …
Spécialisation des templates d’hôtes
Template Linux générique
Même si les distributions linux ont leurs spécificité, en n’en reste pas moins qu’un noyau linux c’est du linux 😀
beaucoup de services sont communs à toutes les distributions:
- snmpd
- crond
- httpd … oups sur debian c’est apache 😀
Ce qui est important, c’est de comprendre ce qui est commun à toutes les distributions.
Ce qui est commun sera un service linux.
Le reste est dépendant de la distribution.
Un serveur linux a quelques services de base pour son bon fonctionnement
on évitera de superviser le service /sbin/init (Je sais c’est null mais c’est un exemple des indicateurs qui ne servent à rien)
pourquoi ?
- sans ce service le serveur ne démarre pas 🙂
- Si le serveur n’est pas démarré, le ping suffit pour nous indiquer qu’il y a un problème 😀
Nous allons donc créer nos templates en suivant cette logique :
- Un template Linux de base
- Des Templates RedHat
- Des Templates Debian
- Faites preuves d’imagination pour les autres distributions 😀
Le template d’hôte de base TH_OS-Linux-SNMP-custom
Nous allons donc créer le conteneur qui contiendra les services de base pour s’assurer :
- Du bon fonctionnement du serveur
- Que nous seront en capacité de superviser le serveur.
Notre template de base aura donc cette configuration :
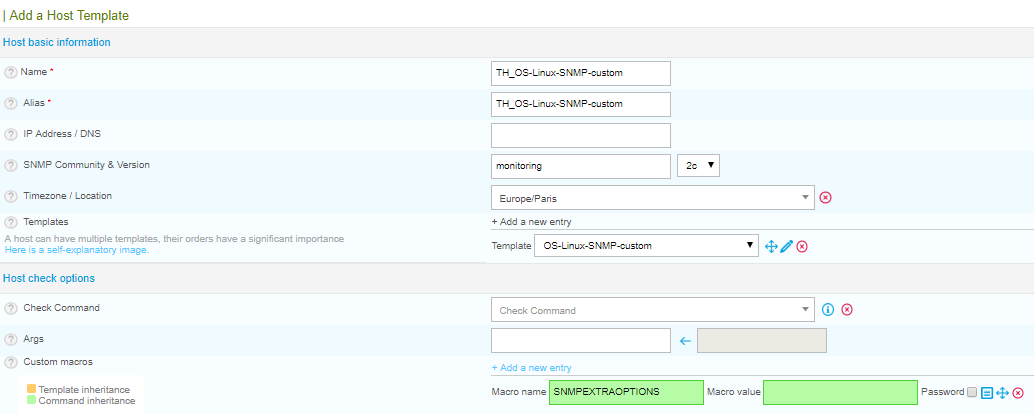
Les champs à renseigner sont donc :
- name : TH_OS-Linux-SNMP-custom
- alias : TH_OS-Linux-SNMP-custom
- Communauté SNMP : monitoring
- Version SNMP : 2c
- Le template custom fourni par centreon : OS-Linux-SNMP-custom
Nous rattacherons les services plus tard.
NB : Si postfix est configuré, et que vous avez créé un contact avec une DL pour les admins Linux, vous pouvez spécifier la liste de diffusion à notifier dans l’onglet notification.
Les template de service de base
Avant de pouvoir superviser un serveur nous devons être sur qu’il est accessible et que les vecteurs de supervision sont disponibles.
L’expérience me montre qu’il y a un vrai évolution sur l’utilisation de la supervision. En effet quand j’ai commencer a faire de la supervision à la fin du siècle dernier, ce qui intéressaient les clients et la détection de pannes.
Un peu d’ITIL
Depuis ITIL est passé par la 😀 .
Des plateformes de hotline (SVP, Helpdesk, peut importe sont nom :D), sont mises en place dans la plupart des sociètés pour signaler un dysfonctionnement. Le but est donc d’anticiper les pannes et non plus de voir les dysfonctionnements. Il est important que le support utilisateur (encore un autre nom 🙂 )ait accès à la plateforme de supervision.Quand ça fonctionne pas la hotline est là informer.
Deux cas sont possibles :
- La supervision à détectée la panne et l’utilisateur final est informé que c’est en cours de résolution :
- Cela permet de rassurer l’utilisateur final
- Cela permet de montrer que les moyens sont mis en place pour prévenir les interruptions de service.
- La supervision n’a rien vu, il faut faire une analyse post incident :
- Quelle est la root cause ?
- Quels sont les indicateurs qui manquent ?
- Quels sont les indicateurs à mettre en place pour anticiper interruption de service ?
Nous verrons dans un autre article comment utiliser les dépendances de services afin d’atteindre ce but.
La démarche
La démarche qu’il faut garder en mémoire et que les indicateurs mis en place sont liés les uns au autre :
- Le serveur ne ping pas, ya rien a voir le serveur est indisponible
- Le service SNMP n’est pas démarré, ya rien a superviser en SNMP
- Le service NRPE (NSCLIENT sur Windows) n’est pas démarré, on ne peut rien superviser via NRPE
- Le service SSH n’est pas démarré, impossible de prendre la main sur le serveur pour résoudre l’alarme.
- Les applications NTiers ne font pas exception
- Base de donnée : aucune requètes si le moteur n’est pas démarré
- Application WEB : Si apache, nginx, … ne sont pas démarré il n’y aura aucune réponse de l’URL
- …
Les indicateurs à mettre en place :
- ping
- Les services :
- snmpd
- snmptrad
- nrpe
- sshd
- crond
- rsyslog
- ntpd
- L’état de santé du serveur
- La mémoire
- La CPU
- La swap
- Les espace disques
Avec ces indicateurs nous pourront être sur que :
- Le serveur fonctionne
- La supervision fonctionne
- Nous pourront prendre la main sur le serveur pour résoudre l’alarme
Voici donc les services :
L’utilisation des ressources système :
- Les TS_OS-Linux-Sys-Usage-%-SNMP héritent directement des templates fournis par centreon
- Les TS_OS-Linux-Sys-Usage-%-SNMP-custom nous permettre de surcharger l’alias des templates en nous adaptons à notre contexte.

Les processus de base :
Même démarche :
- Tous les templates dépendent tu template de service TS_ custom qui hérite du template de centreon, identifié par sont alias qui commence par TS_, il nous permettra de renommer l’alias
- Tous les process linux seront regroupés grace au préfixe OS-Linux-SYS-Process

Nous verrons plus tard comment gérer les espaces disque 🙂
Nous pouvons maintenant rattacher nos services à notre template.
Astuce faites le de façon massive 🙂
Notre template d’hôte contient maintenant tous les services de base dont nous avons besoin :

Nous pouvons voir maintenant comment nos services seront regroupés :
- OS-Linux-SYS-Process
- OS-Linux-SYS-Usage
Tous nos serveurs linux auront au moins ces services de base.
Templates des serveurs type Redhat
Quels sont les distributions impactées
De nombreuses distributions héritent de Redhat :
- CentOS
- Fédora
- …
Qu’est ce qui les différencies :
- Redhat c’est la base, et la base c’est la base 🙂
- CentOs est un Redhat Open Source incluant les paquets non officiels de RedHat
- Fédora est un RedHat orienté poste de travail (Mais ca reste une linux like ReHate :D)
Personnellement je ne mets pas en place de Templates en dehors des branches principales des distributions. Un noyau RedHat reste un Noyau Redhat. On fait du yum 😀
L’histoire des distributions réglée reste à s’attacher aux Versions :
- Gestion des services
- Avant RedHat 6 : Gestion des services via initd
- Aprés Rédhat 6 : Gestion des services via systemd
- Les noms de service (Un exemple) :
- Avant RedHat 6 : le firewall c’est IPTABLES
- Aprés RedHat 6 : le service firewall c’est firewalld
Il est donc important de connaitre l’histoire de la distribution, pour savoir où mettre nos surcharges.
Nous pourrions mettre en place la supervision du firewall sur un serveur RedHat. Dans tous les cas le service s’appellera firewall.
Ce qui titille le neurone 😀 c’est que le service de base c’est iptables depuis des années (avant RedHat 7) et notre template RedHat 7 pourra donc surcharger ce service avec firewalld (et ce n’est qu’un exemple).
Ce n’est pas l’objet de l’article donc nous rattacherons notre template RedHat au template linux de base et nous aurons une supervision de base d’un serveur linux RedHat.
Templates des serveurs debian
De nombreuses distributions héritent de debian :
- Ubunto
- Linux Mint
- …
Personnellement je ne mets pas en place de Templates en dehors des branches principales des distributions. Un noyau debian reste un Noyau debian. On fait du apt-get install 😀
L’histoire des distributions réglée reste à s’attacher aux Versions :
- Gestion des services
- Avant debian 7 : Gestion des services via initd
- Debain 8 : Double gestion initd et systemd
- Aprés debian 8 : Gestion des services via systemd
- Les noms de service (Un exemple) :
- Avant debian 7 : le firewall c’est IPTABLES
- depuis debian 9 : le service firewall c’est firewalld
Nous pourrions mettre en place la supervision du firewall sur un serveur debian. Dans tous les cas le service s’appellera firewall pour garde l’historique.
Ce n’est pas l’objet de l’article donc nous rattacherons notre template debian au template linux de base et nous aurons une supervision de base d’un serveur linux debian.
Conclusion
Au niveau de cette étape ce qui est intéressant :
- Nous avons un template de base avec 10 services
- Les templates spécialisés héritent de ces services
- Nous pourrons spécialiser les services en fonction de l’OS et de la version
Ci dessous les templates mis en place

Le résultat :
- Nous avons un template linux de base avec 10 services
- Chaque distribution hérite de ces services
- Chaque version de distribution hérite de sa propre distribution + des services du template de base
En faisant hérité un serveur d’une distribution et de sa version nous aurons le minimum de base de la supervision système
Faisons maintenant le bilan sur les regroupements des services :
Ce que nous avions avant :
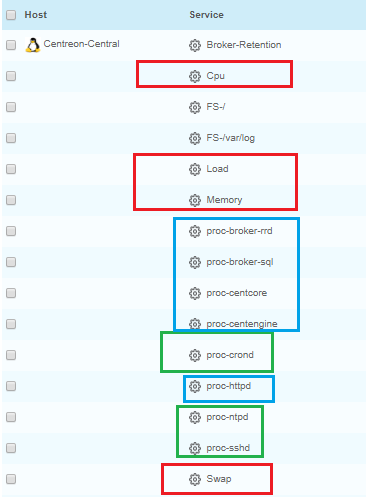
Le résultat obtenu :

- Tous les processus système sont bien identifiés et rassemblés.
- Il en est de même pour la consommation des ressources système.